Two of Safe Software’s XML gurus, Don Murray and Dean Hintz, held an “Ask Me Anything” webinar about XML and JSON yesterday. To paraphrase Dean: “We love XML and JSON because it makes the web work. It allows data to flow in an open and accessible way.” Here’s a recap of a few topics they discussed in this excellent live Q&A.
Where are XML and JSON being used and how are they growing?
XML and JSON are the languages of the web and web services. It’s the way data flows between mobile devices, servers, and different business systems. XML has been used for years as an exchange format, and JSON more recently. They are the basis for hundreds of formats and standards, like CityGML, INSPIRE, and data used by national mapping agencies.
XML and JSON are important because they are an open standard. They are a vendor-neutral way of moving and sharing data, whether that’s between departments or to external vendors and regulatory bodies. Organizations usually leverage many specialized applications, and XML/JSON enable data to be shared between them.
XML vs. JSON – which is better?
As Dean said, “That’s like saying, Karate vs. kung fu, which is better?” There are places where each one shines! JSON is better for mobile, while XML is good for more complex exchange formats and is easier to validate. Complex geometries that are supported in GML are tougher to do in JSON. In the end, it all depends on the data model and what you’re doing with it.
JSON vs. YAML?
YAML is meant to be more human-readable than JSON. It’s used more for messages, while JSON is used more for messages and objects. YAML is not meant for huge datasets as a replacement for JSON. Again, it comes down to the type of applications you’re working with.
How do you easily read and process JSON from third-party sources?
First, consider whether you need to read a web service or a file. If it’s a web service, look at a sample of the data to know what you’re dealing with. Next, determine the nature of the data: if there are a lot of coordinates, it might be GeoJSON. Try reading it in FME with the GeoJSON Reader. Otherwise, try using the JSON Reader.
Next, pick the object that you want to read. In FME, the tree navigation is super helpful to understanding XML/JSON data’s hierarchical structure and choosing which object(s) to read. You don’t want to choose “Select all” here—just pick the object you care about. Within the element called “items” or “features”, you’ll have a single “feature”, which is what you want. This will give you one feature per item so you can work with the specific object you need.
- Dean’s tip for working with XML and JSON in FME: choose a singular element to read into the workspace, not a plural one. That is, pick an element called “recipe” not “recipes”. This way, you get just the object you care about, not a whole array.
Check out our Getting Started with JSON tutorial for a step-by-step guide.
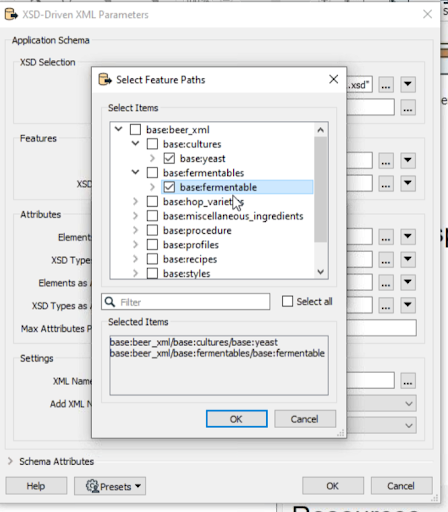 Choosing a singular element in an XML dataset of beer recipes.
Choosing a singular element in an XML dataset of beer recipes.
How do you validate XML/JSON attribute names?
This is a great question, because data should always be validated at the start of any workspace to ensure it’s well-formed!
In the XMLValidator transformer, there are two levels of validation. First, check the syntax to ensure it’s valid XML to begin with. If that passes, you can then check the schema. Configure the transformer parameters to check the file and use the application schema (XSD file) to verify that the attributes are valid. The XMLValidator will output a rich list of issues with their row numbers.
For JSON data, you can use the JSONValidator transformer to validate the syntax.
What’s the difference between using the XML Reader with or without a schema file?
If you use FME’s XML Reader, you are reading the data without looking at the application schema to interpret it. If you want to read an XML file based on the application schema, i.e. the XSD file, use the XSD-Driven XML Reader.
What should you do if you get XML with child items?
Use the XMLFragmenter transformer to break up the XML into parts. This transformer includes a flattening option, which can be selected to turn the content of the XML elements and children into attributes.
- Tip: use the AttributeKeeper or BulkAttributeRemover to keep only what you need as data flows through your FME Workspace. Passing the entire XML file along the workspace instead of just the part you care about will drastically slow down performance.
How do you work with JSON streams in FME?
FME Server Automations are great for working with data streams. Check out our tutorial on FME and Stream Processing.
With JSON, which comes as an array, you want to make sure it’s being output record by record. A lot of services generate json-nl. Sometimes, you might be trying to get all features from a stream but you are only getting a subset, say 500 at a time. If this is the case, check that you haven’t set the Max Features to Read parameter in FME. The server might also be limiting the number of features that can be read. In this case, you can get the data in pieces: query 1-500, then 501-1000, and on.
That wraps up our recap! Watch the whole webinar to dive into all of the questions and answers, including more technical topics, server/automation scenarios, and discussions on upcoming functionality and feature ideas.
Also check out these excellent resources:
- [Webinar] XML-athon with Don and Dean
- [Tutorial] Getting Started with XML
- [Tutorial] How to Read XSD-Driven XML
- [Webinar] 10 Common JSON Problems – Solved!
- [Tutorial] Connect to Anything: Web Services, FME, and JSON
[Blog] The Importance of the OGC & Open Standards

Tiana Warner
Tiana is a Senior Marketing Specialist at Safe Software. Her background in computer programming and creative hobbies led her to be one of the main producers of creative content for Safe Software. Tiana spends her free time writing fantasy novels, riding her horse, and exploring nature with her rescue pup, Joey.



