With the proliferation of event streaming technology, organizations are dealing with a surge in data volumes pushing traditional data processing architectures to the limit. Decision-makers have also realized that the more up-to-date the data they are looking at is, the better positioned they are to make effective decisions. This is where data streams and stream processing become important.
The explosion of data has pushed enterprises to adopt stream processing architectures that can integrate and analyze large, continuous data streams in near real-time. Organizations adopting these technologies gain a significant competitive advantage by reducing the time between capturing data and delivering actionable information to decision-makers.
But what is stream processing? Before we answer that question we need to understand the characteristics of the stream data that stream processing solutions were built to handle.
What are Data Streams?
All data can be categorized as either bounded or unbounded.
Bounded data is finite and has a discrete beginning and end. It is associated with batch processing.
Unbounded data—also referred to as a data stream— is infinite, having no discrete beginning or end and is associated with stream processing. As well as being continuous, unbounded data typically has the following attributes:
- Data records are small in size.
- Data volumes can be extremely high.
- Data distribution can be inconsistent with quiet and busy periods.
- Data can arrive out of sequence compared to when the event happened.
Where Data Streaming Exists
Organizations in almost all sectors are now leveraging data streams as part of their business strategy. Partially, this is driven top-down by decision-makers wanting to gain a competitive advantage. It is, however, a technological shift that has been the enabler.
Sensors and hardware that collect data have become much cheaper (the average cost of an IoT sensor dropped from $1.30 in 2004 to $0.38 in 2020) and accurate in the data they can collect. Infrastructure and big data services have also improved and reduced in price, enabling organizations to transport, store and process the data quicker and cheaper.
The following are the main sources of data streams:
- Business Applications: Data containing customer orders, insurance claims, bank deposits/withdraws, airline transactions.
- Digital Information: Clickstreams, tweets, social media postings, weather feeds, IT network logs, market data, email.
- Internet of Things (IoT): Sensor data from physical assets such as vehicles (geolocation), wind turbines (SCADA), or machines.
In each business sector, although the underlying technology is relatively consistent, the problems that are being solved and the way the technology is utilized varies dramatically.
What is Stream Processing?
Stream processing is a term that groups together the collection, integration, and analysis of unbounded data. It allows organizations to deliver insights across massive datasets on a continuous basis. Typically it is talked about in the context of big data, with low latency and massive throughput key requirements for any solution.
To fully understand stream processing It is helpful to understand the differences between stream and batch processing.
| Batch Processing | Stream Processing | |
| Frequency | Infrequent jobs that produce results once the job has finished running. | Continuously running jobs that produce constant results. |
| Performance | High latency (minutes to hours). | Low latency (seconds to milliseconds). |
| Data Sources | Databases, APIs, and static files. | Message queues, event streams, and transactions. |
| Analysis Type | Complex analysis is possible. | Simpler analysis, including aggregation, filtering, enrichment, proximity analysis, and event detection. |
| Processing | Process after storing the data. | Process and then maybe store the data. |
Stream processing does not replace batch processing. Many organizations are adopting both approaches so they have a solution to handle both batch and real-time workflows.
Another crucial thing to understand is stream processing flips the processing model around. For batch processing, you store the data first (data at rest) and then process it in bulk. This model can be applied to stream data, but then there would be a delay between writing the data out and running the analysis. It also means you would have to store all of the data which can be expensive.
With stream processing, you process the data in memory first and then store it. This seemingly small detail has a huge impact on both performance and how you must design workflows and architect your system. It requires a fundamentally different thought process compared to batch processing.
Because of the infinite nature of unbounded data and the fact stream processing systems are built to handle large volumes of data, when it comes to processing the data, some compromises need to be made in terms of the complexity of processing that is supported. If this wasn’t the case, the large data volumes that stream processing tools can process compared to batch processing would be compromised.
These are core stream processing workflows. A stream processing system will support one or more of them:
- Filtering – Reduce data volumes in memory by filtering an unbounded stream on either attribute values or location, before committing data to disk.
- Enriching – Join the unbounded data to other datasets (databases, APIs) before committing data to disk.
- Aggregation – Summarize the unbounded data by calculating time-windowed aggregations before committing data to disk.
- Event Detection – Detect patterns in memory and then trigger an event when certain criteria are met.
For simple filtering and enriching, data can be processed on an individual basis. For example, for every message that is received assess if a value on the message is above a threshold. If it is, commit the data to a database, if it is not, discard it.
To perform more complex analyses such as aggregation, the data stream must be broken up into buckets for processing.
Breaking Up Unbounded Data for Processing
When running batch jobs, grouping data is easy. Because the data is finite, you can load all of the data into memory, and once it’s all loaded, you can sort and group the data before analyzing it. When working with unbounded data streams the data is infinite so you cannot do this. So, how do you go about breaking the data up into processing groups? You break the data up into time frames called windows.
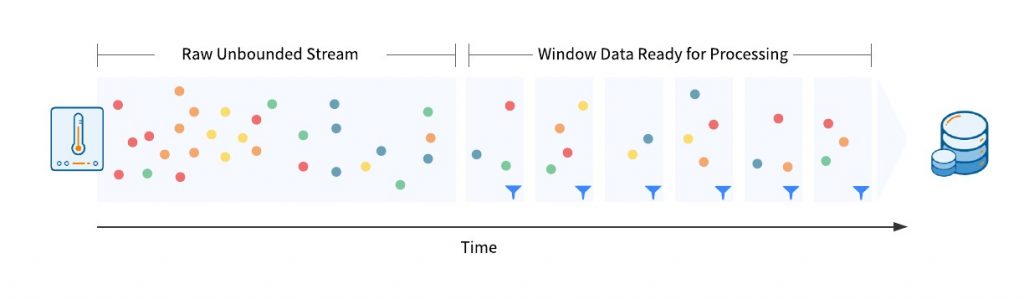
Windowing means that the unbounded data stream is broken up based on time into finite chunks of time for processing. For example, if you are reading a stream from a sensor, and the data points are coming in at roughly 1 point a second, you might choose to window the data into a 1-minute interval. This would mean that the data from the sensor is grouped 1-minute periods for processing.
Is Stream Processing Related to Cloud Computing?
Cloud computing is not a requirement for stream processing, but in reality, any organization architecting a modern stream processing solution will leverage at least some cloud services. Stream processing systems need lots of storage, on-demand compute, and integration with services that only exist in the cloud, such as machine learning and data warehouses.
Performing Stream Processing
There are many stream processing solutions on the market. While each solution addresses a slightly different set of problems, they can be broadly categorized as follows:
- Code-based – Write custom code to receive events from topics in the broker and either write the result back to the broker or another data source.
- Self-hosted open-source – Many open-source tools exist that you can deploy on your own infrastructure, e.g. Apache Flink, Apache Kafka, Apache Spark Streaming.
- Managed Open Source – Cloud providers offer managed versions of the open-source tools, e.g Amazon MSK is a managed Apache Kafka. These solutions offer the same functionality as the open-source tool but the deployment and management overhead is lowered.
- Proprietary – These may be based upon an open-source offering, or they are architected by the vendor from the ground up, e.g. AWS Kinesis Data Streams, Azure Analytics, Streams in FME Server.
Most options require extensive code or queries to be written with only a few having a graphical user interface. FME is one of the options that require little to no coding, and so, is a good option for almost anyone. Learn more about FME and Stream Procesing.

- Introduction to Data Streaming
- Empowering Real-Time Decision Making with Data Streaming
- How Real-Time Data Works & Why You Need It

Stewart Harper
Stewart is the Technical Director of Cloud Applications and Infrastructure at Safe. When he isn’t building location-based tools for the web, he’s probably skiing or mountain biking.



