Change data capture (CDC) means identifying and tracking what has changed in a database so that you can take action, like updating your data warehouse or generating other outputs. The idea is to replicate a dataset using incremental updates so that you don’t have to copy your entire database every time a table gets updated.
For example, using a CDC workflow to maintain a data warehouse can enable your team to perform analytics and generate business intelligence. It can also be useful for maintaining separate representations or subsets of the data for different purposes. Say you have an internal geodatabase that gets updated continually throughout the day, and you want to share it via a public web map. This is where creating an automated workflow to extract, process, and incrementally load the changed rows can keep the web map up to date while saving huge amounts of computing time and network traffic.
There are several ways to do change data capture, and the best method depends on your data sources and what information and tools are available. Let’s compare some common ways to identify changes in a database, and how to implement each one in an automated environment. The methods we’ll cover include:
- Leveraging built-in CDC tools or transaction logs offered by SQL Server, Oracle, and other systems
- Using triggers to take action whenever the data is updated
- Comparing timestamps to determine which rows have been recently updated
- Differencing the whole database or table with its previous version
See also: This blog focuses on checking for updated data, but you can also check for a changed schema or structure. Learn more about this in our webinar on Schema Drift.
1. Leverage Built-In Change Tracking Functionality with Log-based CDC
Many systems have built-in functionality for tracking changes: Esri data/software like Geodatabase and ArcGIS Portal have Versions and Archiving, Smallworld has Alternatives, Oracle has Workspaces, and others maintain transaction logs or change logs. If you’re not afraid to dive into the database core, this is a logical way to let the database do all the tracking, freeing you to leverage the results in your CDC workflow.
Your workflow should extract recent changes from the log table, filter what was inserted/updated/deleted, and then take action in the destination system(s) – for example, apply the corresponding insert/update/delete to your data warehouse or generate a report showing what changed.
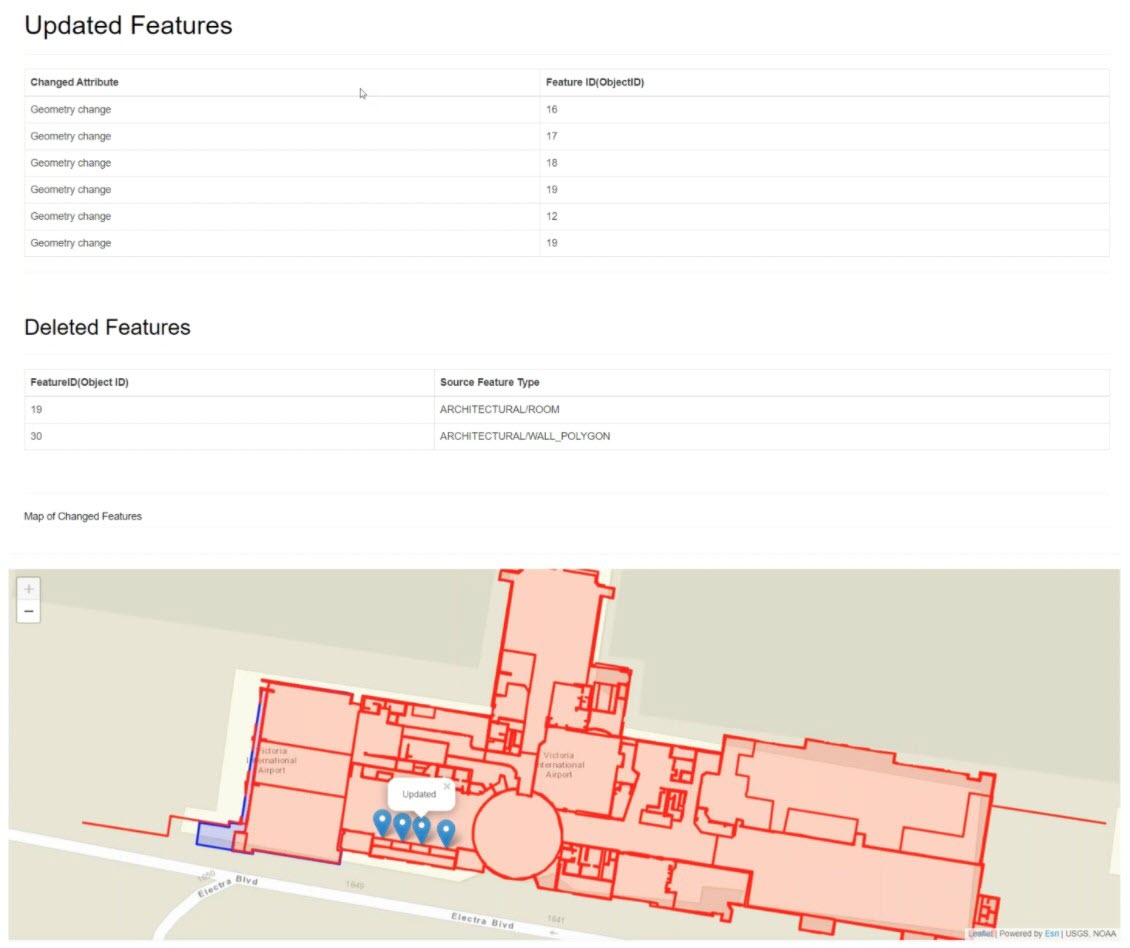
If you’re interested in using change logs to keep a destination system up to date, watch the “Log-based change data capture” section of our Changing Data webinar, where we demo how to use FME to read from a SQL Server transaction log and update an ArcGIS Online web map. In FME, you can use a WHERE clause in the Reader or the SQLCreator transformer to get recent changes from a log table.
The “Reader-specific change detection” demo also shows how to leverage built-in functionality when adding a Reader for Geodatabase, Smallworld, or Oracle. FME will flag features as inserted/updated/deleted in the ‘fme_db_operation’ attribute, which you can then use to take action in the destination system. To achieve total automation, run the workflow as part of an FME Server Automation to ensure your endpoints stay up to date as the source database changes.
2. Set up your own Change Log using Database Triggers or Webhooks
What if the database doesn’t come with a change log or built-in change tracking tool? If you’re working with a database, you can create a change detection table (i.e. a “shadow table”) and set up a trigger to update it whenever something changes. This table will serve to keep track of every change that occurs.
After setting this up, you can leave the database to keep it up to date automatically. You’ll then create a workflow to connect to this shadow table, filter, and take action as usual. The drawback of this method is that the extra table adds clutter to the database. But if that’s not a concern, then it’s a straightforward way to make the database do the work.
If you can’t or don’t want to use database triggers, webhooks can do a similar thing. In FME Server, set up an Automation with a webhook trigger that launches your FME Workspace whenever something happens.
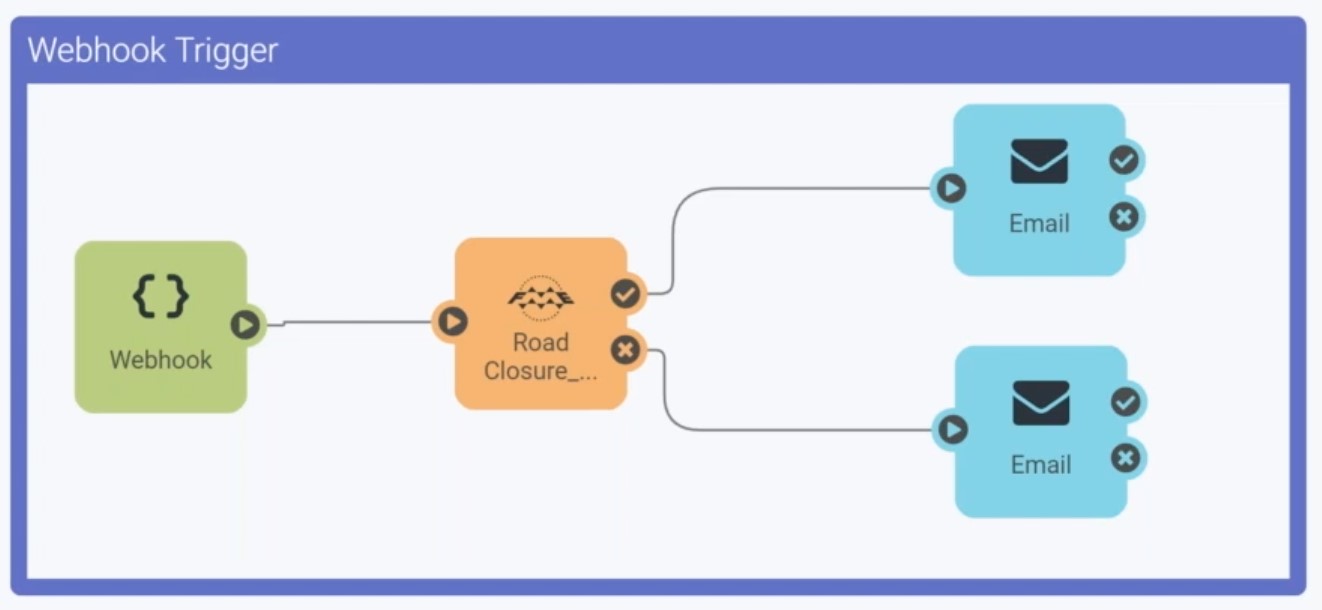
To see a demo where we build an automated FME workflow to read a shadow table and process the changes, watch “Database Triggers / Webhooks” from our Changing Data webinar.
3. Use a Timestamp Column
If you’d like to avoid combing through the database’s transaction log or change tracking feature—or if the option to do so isn’t even available—then you can use a column or attribute to record when a row changes.
This can also be a desirable method of change tracking if you’re looking to extract changes that are specifically tied to date ranges, like year-over-year differences. Using your DBMS or FME, add a field to record the date/time that each row was last modified. Then, use this field in your CDC workflow by filtering on this attribute and extracting just the changed rows.
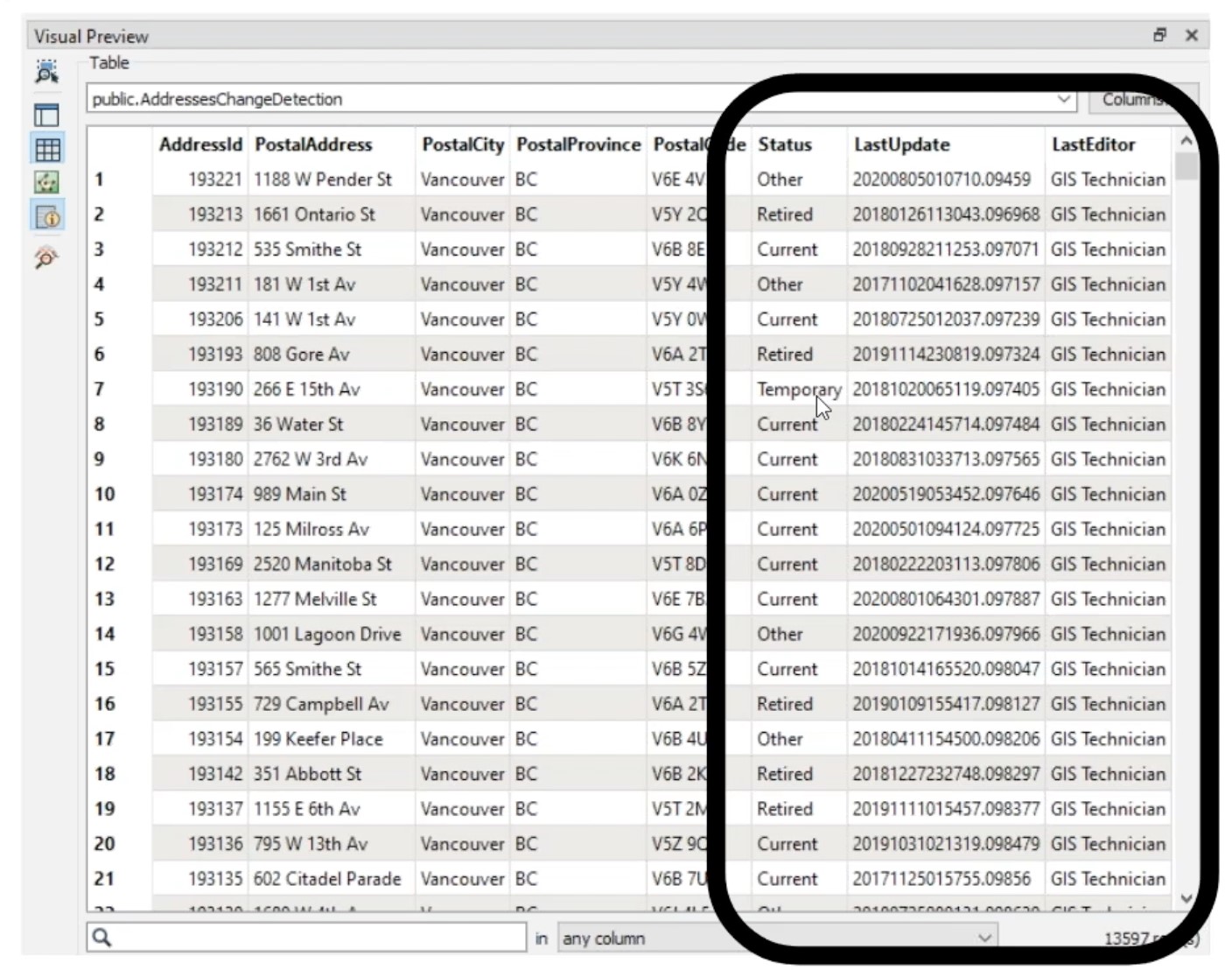
To leverage a timestamp column in FME, use a WHERE clause in the Reader parameters to read only data that was last modified within a certain date range. Watch a demo that covers how to set up the Reader parameters and transformers in the “Modification time stamps” section of our Changing Data webinar.
4. Perform Table Differencing with the ChangeDetector
Comparing the current state of the data with its previous state is the most thorough and precise way of checking for changes, and useful when no existing change tracking is in place. This is often the case for users who don’t have access to change logs, don’t have permissions to add a shadow table or timestamp column, but still need to track changes in a dataset in a repeatable, automated workflow.
In FME, this is what the ChangeDetector transformer is for. It reads the original dataset and the updated one, then outputs which rows were updated, inserted, deleted, and unchanged. You can then use the “fme_db_operation” attribute (which is set by the ChangeDetector) to define how to handle the features in the output system.
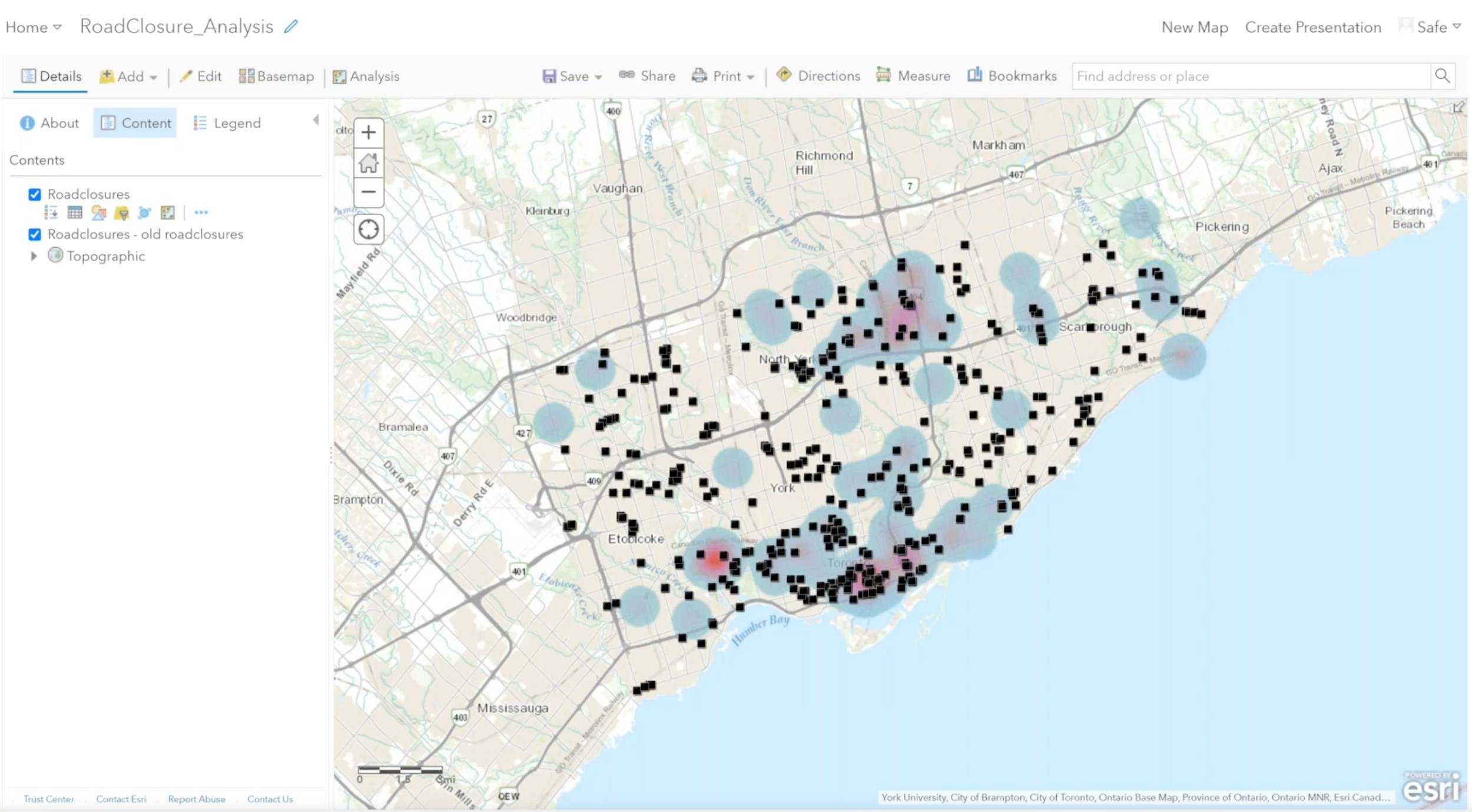
To compare existing and new geometry data, for example, parcel polygons, the ChangeDetector has a couple of helpful parameters, including a tolerance value for defining how much variance to allow before a geometry is deemed ‘changed’. To read more about tolerance values and change detection, read our Change Detection blog and check the ChangeDetector documentation for details on how to set this transformer’s parameters.
A note on performance: for datasets containing more than a few hundred thousand rows, differencing the whole thing might have inadequate performance. You’ll achieve better performance by limiting the number of columns/attributes you check, but if this is still insufficient, then one of the above methods of change detection might be more suitable.
Watch “Managing Changing Data with FME” to see how to use the ChangeDetector to compare attributes and geometry on a variety of data types. We also demo how to use Automations for a hands-free workflow that you can run continuously in the background. For a real-world example, the US government’s Bureau of Land Management uses the ChangeDetector to integrate 10 spatial data sources and keep their repository up to date. Check out their presentation to see how their workflow compares the current version of the database with the previous version, using incremental loading to drastically reduce the processing time for large changing datasets.
The method you choose for CDC really depends on what formats you’re working with and what tools and information are available. No matter which method you use, I hope you’re relieved to see that the solution is straightforward. There’s no need to play “spot the difference” on data – you can set up an FME workflow to handle change tracking automatically.
Try out your own change data capture workflow by downloading a free trial of FME, and check out the below resources to get started:
- Tutorial: Change Detection
- Tutorial: Updating Databases
- Tutorial: Automating Change Detection workflows in FME Server

Tiana Warner
Tiana is a Senior Marketing Specialist at Safe Software. Her background in computer programming and creative hobbies led her to be one of the main producers of creative content for Safe Software. Tiana spends her free time writing fantasy novels, riding her horse, and exploring nature with her rescue pup, Joey.