 Parallel Processing can be a big deal in terms of performance. Modern computers have multiple cores and spreading processes over these cores makes the most of the available computing power.
Parallel Processing can be a big deal in terms of performance. Modern computers have multiple cores and spreading processes over these cores makes the most of the available computing power.
FME takes advantage through parameters that define multiple processes. Plus transformers that parallel process also have an “Input Ordered” parameter, which is another performance-enhancing tool.
Except… we saw support cases and test results that suggested we ought to redesign the parallel processing setup; so for FME 2019 that’s exactly what we did!
![]()
How Parallel Processing Changed in 2019
In brief, we removed the parallel processing option from all individual transformers in FME 2019:
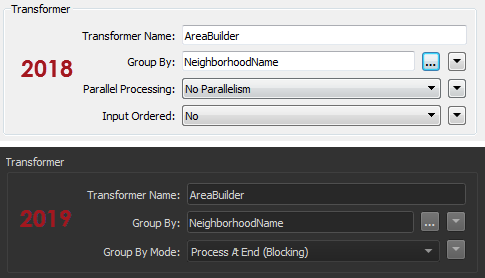
Notice there is no Parallel Processing parameter (plus Input Ordered is now Group By Mode). But don’t worry! Parallel processing is still available. Only now it’s available solely as an option on custom transformers.
If you’re not that interested in why we made the change, then skip forward to “FME 2019 and Parallel Processing” below.
But if you want to know the reasons, carry on reading…
![]()
The Problems with Parallel Processing
Parallel processing is complicated. Perhaps more complicated than our interface appeared. Users need to plan how many processes to create and how many features to handle per process. Plus there are complications like the order of features (which can change when parallel processing).
In short, with FME2018 we felt there was more chance that a user would slow their workspace down, rather than speed it up. There are a few reasons for this…
Interface Design
In design terms, the complexity of parallel processing is compounded by the prominence of its parameters. We belatedly realized that the functionality should not appear at the top of each transformer dialog! It’s confusing and it doesn’t relate to the core purpose of a transformer.
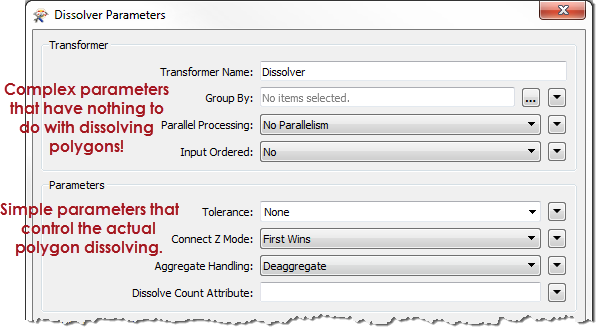
Imagine if the biggest buttons on your TV remote were for fine-tuning picture color! So that’s one reason to move parallel processing to somewhere less obvious. The mix of complexity and prominence encouraged incorrect use of parallel processing. The most common mistake was the number of processes…
Multiple Parallel Processing
As you might know, there is an overhead to starting and stopping FME processes. There’s also an overhead in passing data from one process to another. So excess processes slow the translation. The ideal scenario is to have fewer processes, working on more features. When there are lots of small jobs, the extra overhead is greater than the gain from parallel processing. The overall translation is slower, rather than quicker.
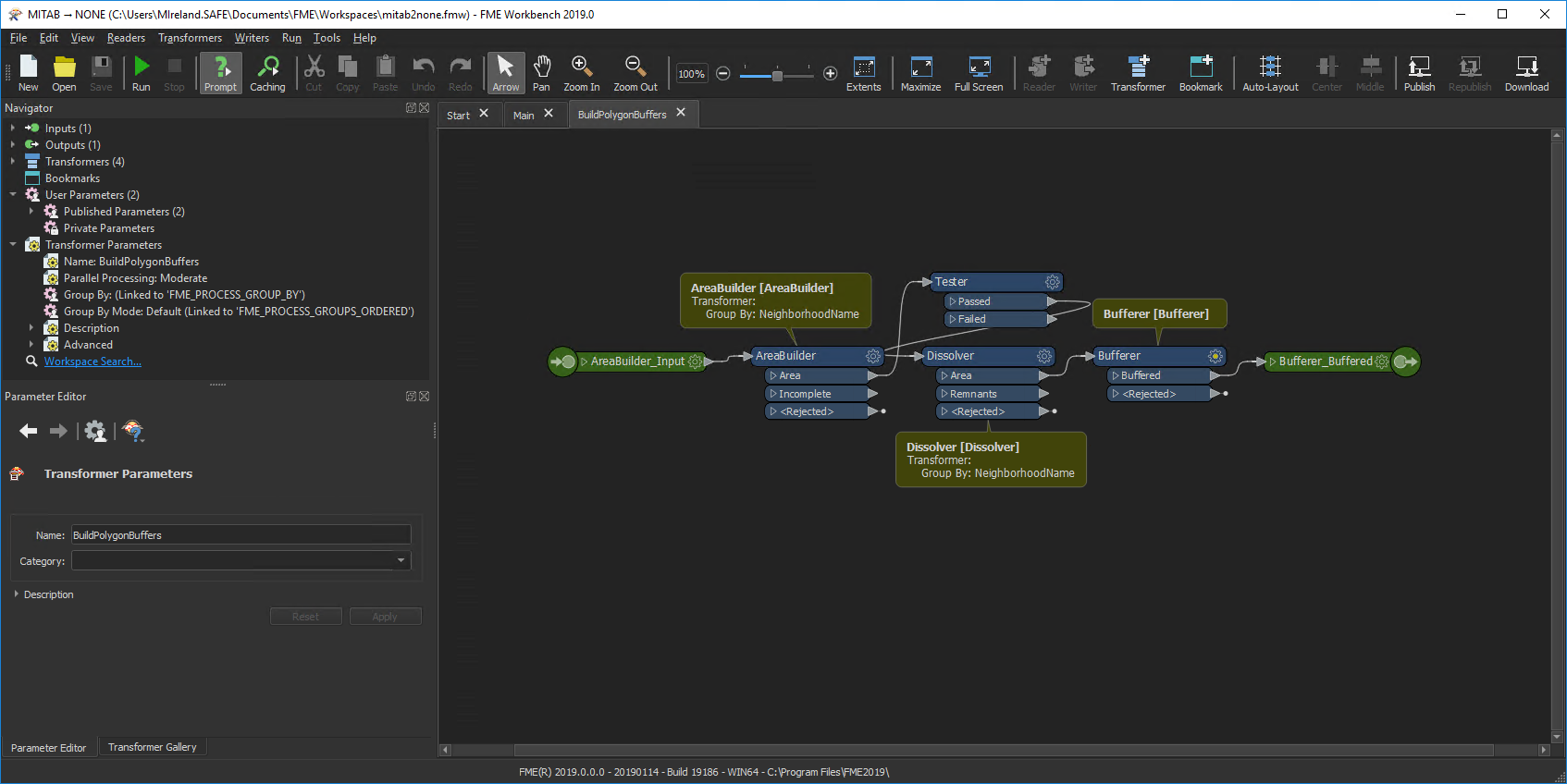
Take this example workspace in FME2018:
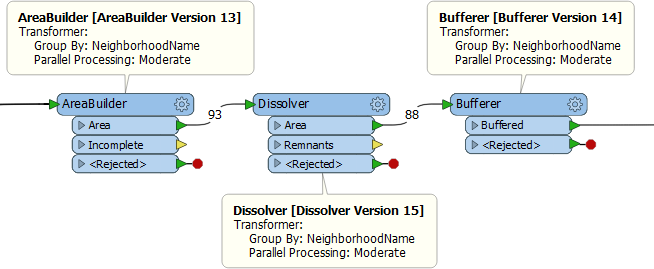
Let’s start by busting a myth. You might think that because all three transformers are set to parallel process data, that they might all start up multiple processes simultaneously, bringing the computer to its knees. That’s not the case. The Dissolver doesn’t start any processes until all of the AreaBuilder processes are complete. So the number of processes won’t spiral out of control.
That’s good.
However, all three transformers group by the same attribute!
Let’s say there are 8 neighborhoods. Each transformer will create 8 processes. We know the workspace won’t run 24 processes simultaneously. However, it will run 24 processes in total. It doesn’t need to, though, because the groups are going to be the same for each transformer! It could do the same work in just 8 processes.
As I’ll demonstrate later, if the author had made this into a custom transformer and applied parallel processing, then there would be fewer processes. So, that’s another reason for our change. The new design encourages the right behaviour so it’s more likely an author will do the right thing, even if they aren’t aware of it!
Non-Parallel Transformers
An added benefit of parallel processing with a custom transformer, is that it parallelizes all transformers, whether or not they are group-based. As an example, let’s put a Tester transformer into the previous example:
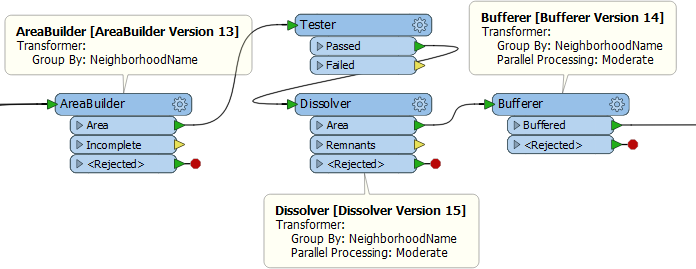
With this layout the 8 processes of the AreaBuilder then converge back to a single process for the Tester. They are then divided back into 8 processes for the Dissolver. Apart from the stopping/starting processes, the Tester is inefficient because it is a single process.
If this were created in a custom transformer, then parallel processing also applies to the Tester, and that makes it more efficient.
Input Ordered and Parallel Processing
The Input Ordered parameter is interesting because it was tied directly to parallel processing, both in our code and by virtue of being adjacent in the parameters dialog:
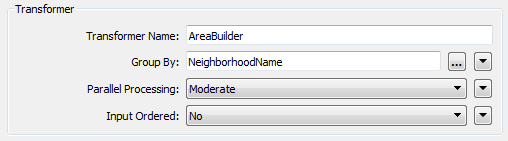
Because it’s in the same block of parameters, it looks like it must be related. In fact it isn’t. At least, it’s related in that they are both performance-related; but there’s no reason your data has to be ordered to use parallel processing, or that ordered data must be processed in parallel.
So we decoupled these two parameters to reduce the confusion, and to prevent users applying them in error. In particular, the Input Ordered parameter also controls what is processed in a group, so it’s especially important to not misuse it. It also got renamed and new option names to make it clearer what it is for:

So that’s why we made those changes. Now let’s see what parallel processing looks like in FME 2019…
![]()
FME 2019 and Parallel Processing
Parallel processing in FME 2019 is now restricted to custom transformers. That’s not a new capability. It was always possible to parallel process data that way. But – for the reasons mentioned above – this is now the only way to parallel process data.
Let’s take the previous example, now in 2019:
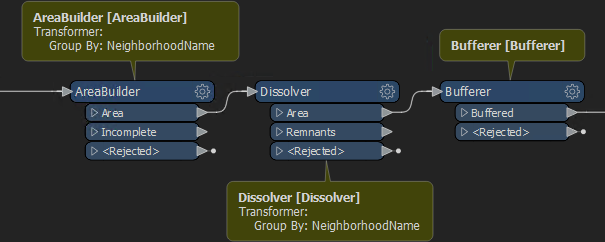
Obviously there are no Parallel Processing options any longer. So, I convert this into a custom transformer and set parallel processing in its parameters:
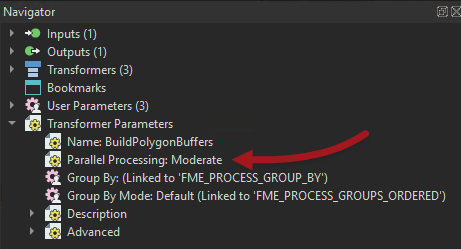
Notice that turning on parallel processing automatically adds a Group-By published parameter (you can’t have parallel processing without a group to divide the data by). So I return to the main canvas, open the parameters dialog, and set the Group By parameter to NeighborhoodName:
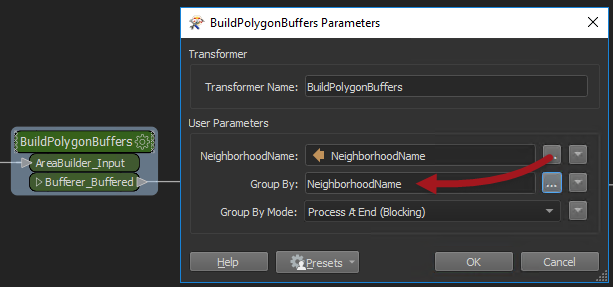
Now when the workspace runs, there is a separate process per group. But, importantly, each process covers all three of the transformers, so there are fewer processes starting.
Additionally, if we add an extra transformer – like this Tester…
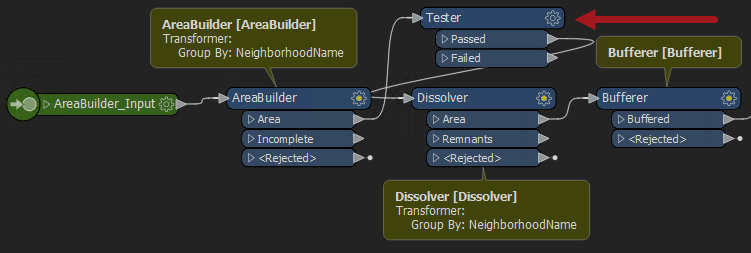
…it too runs in parallel, which is an added bonus.
Of course, you don’t need to be very observant to notice that NeighborhoodName appears twice in the transformer dialog:
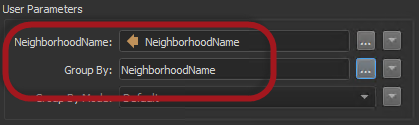
Why is that?
Unnecessary User Parameters
Recall that FME publishes all attributes used in a Custom Transformer automatically. This lets the transformer be used in multiple places, where (in this example) “NeighborhoodName” might not be available. So FME automatically made the first of these published parameters when the custom transformer was created, and the second when parallel processing was activated.
Do we need both? Well, that depends where I’m using NeighborhoodName. I can remove any reference to it from Group-By parameters because the whole custom transformer is now one large group-by. If I’m not using NeighborhoodName anywhere else then, yes, I can remove that first published parameter. I don’t need to use it.
But if – for example – I was using NeighborhoodName in the Tester transformer, then I might want to keep the first published parameter. The first prompts me for the attribute to test by, the second prompts me for the attribute to group by.
Here I’m going to remove the parameter created with the custom transformer.
So first I unset the Group-By parameter in each individual transformer. Then I remove the user parameter; not by deleting the parameter itself, but by unchecking that attribute from the Input port:
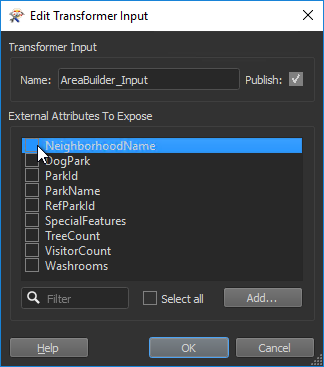
This hides the attribute and – it no longer being necessary – also removes the published parameter automatically.
If I do remove an attribute reference this way, then I should definitely check the custom transformer to see if any parameter became flagged as incomplete (turned red). This would indicate that I’d used the attribute somewhere I hadn’t yet dealt with.
![]()
FAQ
| Q) What if I want to apply parallel processing to just a single transformer? A) To apply parallel processing to a single transformer, you’ll need to wrap it in a custom transformer. It’s a little more inconvenient, but we think the overall set-up is better. |
| Q) What if I want to apply parallel processing to a single transformer inside a custom transformer? A) To apply parallel processing to a single transformer inside a custom transformer, you would wrap that in its own custom transformer. Remember that you may nest custom transformers inside one another. |
| Q) What if multiple transformers need parallel processing, but with different groups? A) If multiple transformers need parallel processing, but with different groups, then wrap each section inside a separate custom transformer. |
| Q) I found an individual transformer with the Parallel Processing parameter still there. Why is it still there? A) Our updates are a little more involved than just removing the parameter from a GUI, and there are a few transformers we haven’t updated yet. Later FME versions may exclude the parameter and so we still recommend the custom transformer method in all cases. |
![]()
Summary
In short, the important issue here is performance. Workspace authors always look to gain a performance advantage and using parallel processing is an obvious method to do that. Unfortunately, it was a little too obvious. We felt that new users could – in attempting to speed up their translations – actually slow them down.
 That’s why we moved the parallel processing parameter to a place where it’s naturally better performing.
That’s why we moved the parallel processing parameter to a place where it’s naturally better performing.
Incidentally, you probably noticed the above screenshots of FME 2019 are in “dark mode”. That’s just one of the other useful updates we hope you’ll enjoy in this upcoming release.


Mark Ireland
Mark, aka iMark, is the FME Evangelist (est. 2004) and has a passion for FME Training. He likes being able to help people understand and use technology in new and interesting ways. One of his other passions is football (aka. Soccer). He likes both technology and soccer so much that he wrote an article about the two together! Who would’ve thought? (Answer: iMark)



