 One of the best things about working from home is that my office looks out over the garden, and I can watch squirrels gathering food and caching it away for the winter.
One of the best things about working from home is that my office looks out over the garden, and I can watch squirrels gathering food and caching it away for the winter.
It’s annoying that they raid my bird feeders to do so, but I suppose it’s very important to them. They collect food in the summer months and stash it away for quick access in the winter.
I don’t know if our developers were watching squirrels too, but FME2018 has a very similar device for caching data. I’ve promoted Feature Caching in webinars and on the world tour, but sometimes I forget not every user watches or attends these events.
Plus, even though this is a big deal for workspace development, it’s not obvious that this functionality even exists.
So this blog post is about Feature Caching in FME 2018. I’ll cover what it is, how it works, what the uses of cached data are, and then provide some tips and tricks for the functionality.
I’m going to try and provide something for everyone, so even if you already know about this functionality, do read on…
![]()
What is Feature Caching? How Does it Work?
Just like the squirrel, Feature Caching in FME is simply storing data away in order to have easy access to it when required.
I turn on caching by choosing Run with Feature Caching from the Workbench menubar:
There’s also – you might notice – a toggle button on the toolbar. Once activated FME now caches data as it is processed:
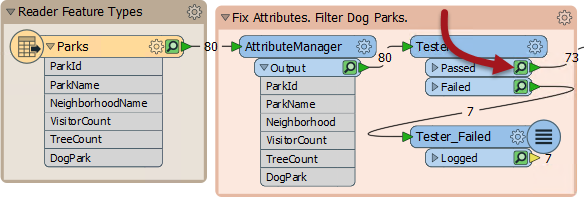
The green icon represents cached data for that particular step. Above you can see that both Tester Passed and Failed features are stored in a cache, and I can even hover over the cache with my mouse to see the data being stored:
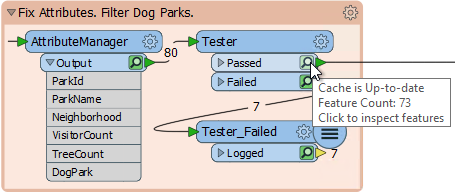
So caching data is really easy. Just turn on the functionality and run the workspace. Of course, there is overhead in caching data, and the workspace will be slower, so you might be wondering what the use of it is…
![]()
What are the Uses of Caching Data?
If you’ve used FME before you might have noticed that Run with Feature Caching replaces Run with Full Inspection on the menubar. That’s because inspection can use cached data. I can click the green icon to view that particular cache, or select a number of transformers, press Ctrl+I, and inspect all their data:
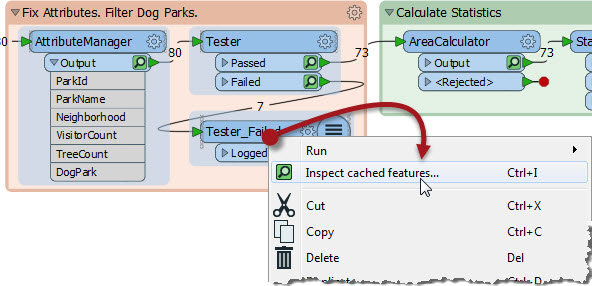
This is great. It means I can inspect whatever data I want without having to place Inspector transformers beforehand. If the results of the AreaCalculator (above) were not what I was expecting, I can inspect the data both before and after in order to diagnose the problem.
But as great as this is, the bigger use is in something we call partial runs.
Partial Runs
Let’s say, in the above workspace, I make a change to the AreaCalculator transformer. The effect on the workspace is this:
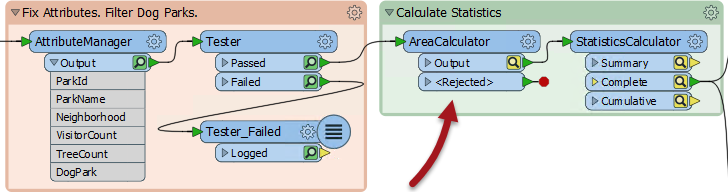
The cache icons on the AreaCalculator, and any transformers further along in the workspace, have turned yellow. This denotes that their contents no longer match what would be actually be produced by the workspace. I can still inspect the data there, but the yellow icon tells me the cache is “stale”.
But what’s more important is that clicking on the AreaCalculator pops up some new run options:
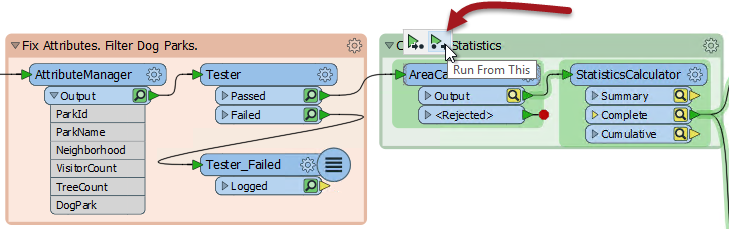
Run From This means that the workspace runs from this point onwards. It doesn’t need to run anything before that point because the data is already available in the caches! This is where we earn back the time spent caching data. Because the Tester has up-to-date caches, the AreaCalculator can use that data instead of running the first part of the workspace again.
Another way to run the same thing is click on a writer feature type and choose Run To This:
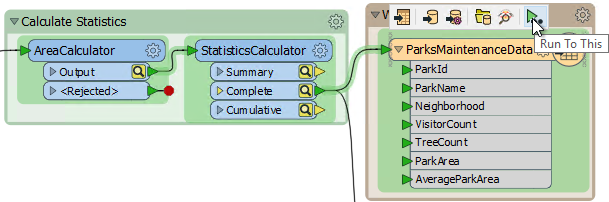
Notice how the parts FME runs are highlighted in green. That way you can see FME reaches back through the workspace until it finds a valid cache.
So that, in a nutshell, is Feature Caching and Partial Runs. Of course, like any FME functionality, there are various ways in which the tool can be applied to our advantage…
![]()
Feature Caching Tips and Tricks
One of the best uses for Feature Caching is for caching the results of web services. Let’s take this workspace that I created to generate a web page showing FME World Tour events:
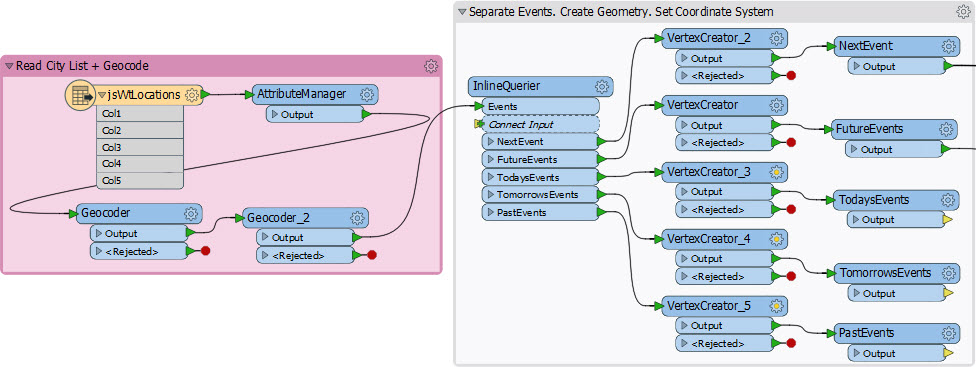
The part with the InlineQuerier took me a little while to get right, and I had to run the workspace a few times. But look, there are two Geocoder transformers before it! One geocodes the point, the other fetches its timezone (did you know we could do that?) With 70+ records it took several minutes to geocode the data and I didn’t want to have that happen every time I tested the InlineQuerier.
Well, with FME 2018 I didn’t need that to happen. I turned on caching so that the Geocoders cached their data. Then I could run the InlineQuerier in a second by having it use the caches. So Feature Caching is a huge benefit when using slow network resources like databases and web services.
Simultaneous Runs
But really caching is helpful for any large dataset, especially when you are starting to develop a new workspace. Lets say I am creating a workspace, and I start by adding a reader to read a database of five million address records:
Normal procedure is to start adding transformers to the workspace, then test them by running the workspace. But… with FME 2018 I turn on Feature Caching and run the workspace immediately. Why? Because while FME reads and caches the data, I can continue developing the workspace, at the same time!
Then, by the time I have my first transformers in place and set up, FME will have read the data and cached it, ready to use directly on the transformer.
In short, I can both run and develop the workspace simultaneously! Time spent waiting to read or transform data can be employed more usefully.
Templates and Caching
Templates have been around for a while and are a great way to store a workspace and its data together in a single file. And in FME2018 the definition of data extends to existing feature caches:
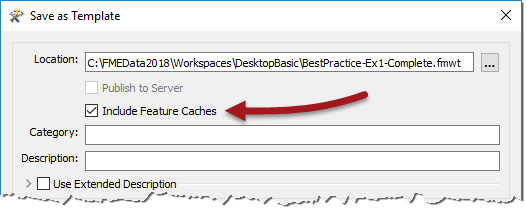
So now you can save your workspace with its caches, and reopen it later with the caches ready to use. You might never have to run the full workspace ever again!
Collapsed Bookmarks and Caching
As I mentioned, one drawback of Feature Caching is a performance loss creating the initial caches, as obviously both time and system resources are used. Plus you have to cache the entire workspace and not just the parts you are interested in, right? So if I run this workspace, ALL of the transformers get cached:

Right? Well, no. It is possible to “turn off” caching on parts of a workspace. You do that by simply collapsing the bookmark around it (another new capability for 2018):
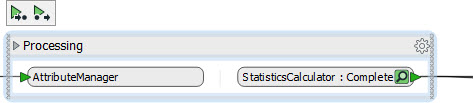
Now I run that workspace and FME caches only the final, connected output port. In this case the StatisticsCalculator:Complete output port is cached, but nothing else is. That speeds up the processing by reducing the amount of caching.
In short, if you aren’t interested in one part of a workspace, hide it in a collapsed bookmark to speed up the caching process.
Junctions
Let’s say I have this bit of workspace, and want to run both branches that exit Geocoder_2:
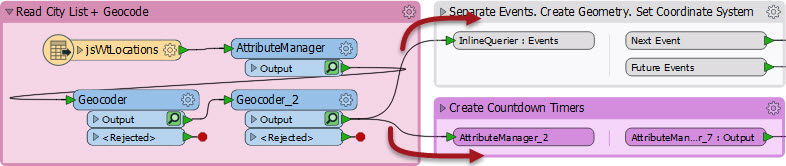
I can run one or the other (using Run From This on the bookmark itself), but to run both I have to select Geocoder_2 and choose Run From This. Of course that means the Geocoder itself will run, which I don’t really need. So in this case I simply add a Junction transformer:
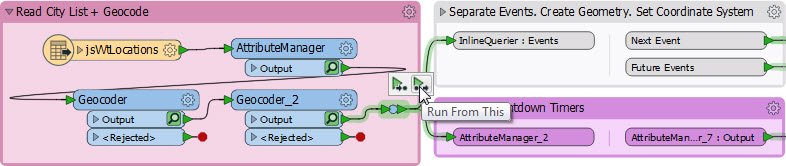
Now I can Run From This on the Junction and not have to re-run Geocoder_2.
Incidentally, the upcoming FME2018.1 is updated to prevent a Junction transformer making other transformer caches stale. Since the Junction transformer does nothing, it won’t affect the data at all anyway.
![]()
Why Not Server?
Here’s a question that I’ve been asked, and my colleague Jen has been asked, and our co-founder Dale has been asked: How does Feature Caching integrate with FME Server?
The short answer is that it doesn’t, and that we don’t plan on any integration.
But if you’re asking so often, there must be some confusion. Let me try to clarify: think of this functionality as being a workspace “authoring mode” or “design mode”. It’s intended that you use caching to construct a workspace because that’s when a partial run is useful. Each time you add a new transformer you can test its operation by just running that transformer, not the whole workspace.
But in production – and especially on Server – you turn caching off, because you aren’t editing the workspace and because the end user won’t want to do a partial run. The only time a cache is useful on Server is for reading datasets and hitting web services, and there is already a caching option on the FeatureReader transformer for that:
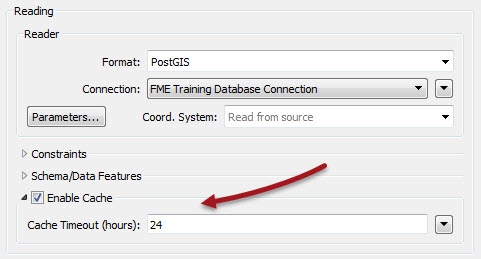
Here I’m reading from a PostGIS database, but I’m also caching that data for a period of 24 hours. So if I’m publishing the workspace to Server I don’t worry about creating caches in Desktop and uploading them. Using this option the Server engine creates the cache automatically, and refreshes it automatically too.
If there’s any other data cached in Desktop that you want to reuse on Server (for example cached Geocoding data) then save the geocoded data with a writer, remove the Geocoder from the workspace, and put in a reader to read the saved data. Then you read the data on Server, not the web service.
In other words, Server is for using on more permanent data; datasets, not caches.
![]()
Spatial Memory and Caching
I read that – just like FME – squirrels have a really strong spatial memory. It’s how they manage to retrieve their cached food. I also found out that tree squirrels don’t hibernate and are so constantly active that a group of squirrels is called a scurry! That too sounds a lot like FME. I hate to suggest it, but maybe we should have an FME Squirrel mascot, instead of the FME Lizard!
Anyway, if you want to know more about caches – data, not nuts and berries – don’t forget we have a training course called Upgrading to FME Desktop 2018 taking place on June 27th. It’s free, so if you are planning to upgrade to 2018, or have done recently, why not sign up? You’ll learn about some of the other new functionality that’s now available, from one of our top FME experts.


Mark Ireland
Mark, aka iMark, is the FME Evangelist (est. 2004) and has a passion for FME Training. He likes being able to help people understand and use technology in new and interesting ways. One of his other passions is football (aka. Soccer). He likes both technology and soccer so much that he wrote an article about the two together! Who would’ve thought? (Answer: iMark)



