Introducing the USCensusCaller, a new FME Custom Transformer. Here’s how to use it to leverage freely available US Census data, plus how it works, and why this matters.
I have always been interested in demographic and geographic data. I keep a collection of atlases from past eras on my bookshelf just so I can pore over the historical tables, charts, graphs, and maps when I have a spare moment of curiosity. Luckily – moments of nostalgia aside – the technological age has given us Open Data and APIs in place of atlases. A fair trade.
Census data has been on my radar since my undergraduate studies: my urbanism professor once assigned a research project to analyze the demographics of my own neighbourhood in Montreal and I quickly became fascinated with the power of data to inform us about our world.
The Idea: Automatically Grab Census Data via API Calls
Thanks to a recent Safe Software demo development marathon and an idea sparked by fellow Safer Roger Aikema, I had the opportunity to take a look at the US Census data portals and API. The amount of data available is astonishing. As I’m sure many people find, downloading chunks of census data to a local machine is tedious, so with help from colleagues Andrea Eisma and Mark Stoakes, I worked to provide an automated system for grabbing only the desired census data through a series of API calls from within FME.
The Census: Striving for Insights, Not Stockpiles
Data enriching and business intelligence are terms that get thrown around a lot – and for good reason. The amount of data accumulated on a daily basis is becoming incomprehensibly large. Consequently, the focus for decision-makers has to be on harnessing the available data for insights rather than simply stockpiling it. Smart businesses and communities are striving to be data-driven rather than just data rich.
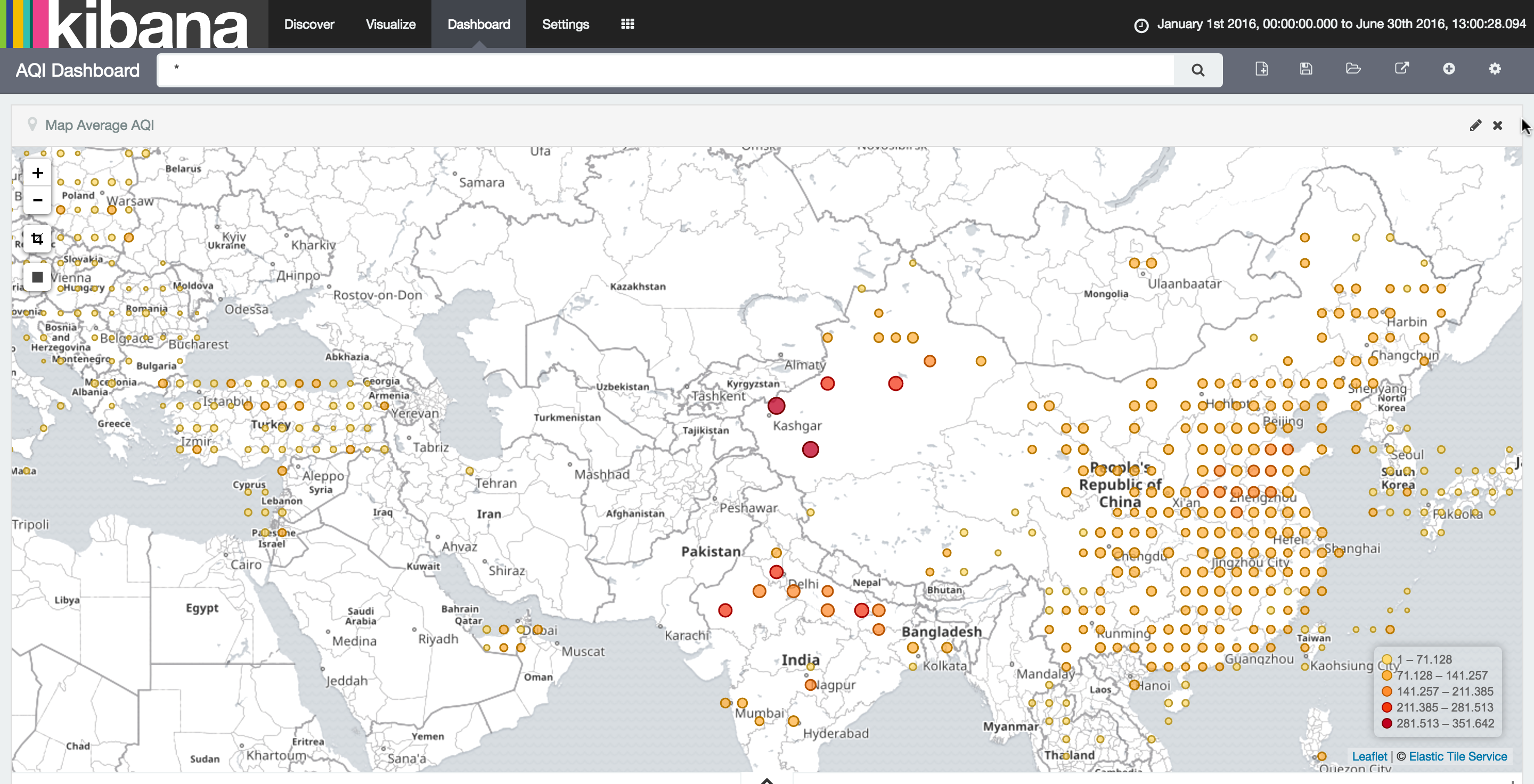
The US Census Bureau has done a lot of stockpiling. And while there are more advanced paid data enriching services out there, the US Census serves their data for free. This sparked the idea for the USCensusCaller.
The database accessed by this transformer selectively compiles variables (somewhat like columns in a table or like attributes of features within FME) from the American Community Survey (ACS) and the US Census. These two datasets are similar, but they differ in their sample size, frequency, and variables. The ACS happens more frequently, but samples less of the population, providing estimates concerning (mostly) economic variables. The US Census happens less frequently but samples more of the population, garnering more precise demographic information. This transformer gives users the choice between the two datasets due in part to differences in variables and in part to some limitations to the API call – more on that below.
The Application: A Hypothetical Business
To get into the mental space of this project, I imagined owning a small chain of coffee shops spread over an urban area, and wanting to know more about my customers. I imagined creating new data in a variety of time-consuming, ineffectual, or costly ways in order to direct a new marketing campaign, for example. Alternatively, I realized I could grab census data for the areas surrounding my stores for free. It seemed like a no-brainer to at least try to tap into the census.
The Technical: Inside the Custom Transformer
![]()
Without going too in-depth, I’ll cover the basic processes within the USCensusCaller. At a high level, it is built upon three API calls chained together to output census data for an area based on input points of interest. (A free API key can be provided as a transformer parameter, but is only needed for large or repetitive calls.)
1. Dealing with points
The transformer assumes you have point data in the LL84 (lat/long) coordinate system. Luckily, this is easy to come by in FME as long as you have some kind of location information. A coordinate transformation followed by a coordinate extraction allows the point data to supply the spatial query to TIGERWeb.
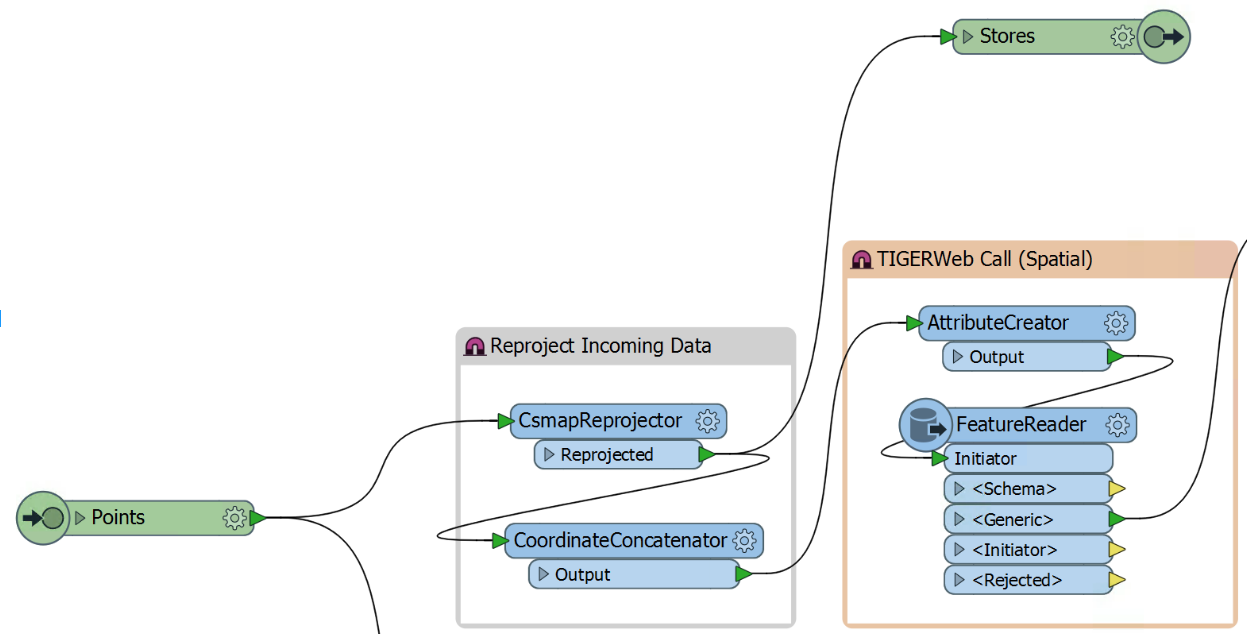
2. TIGERWeb query
TIGERWeb is the spatial side of the US Census Bureau. It holds spatial data for all the census geographic areas. Here a FeatureReader grabs the GeoJSON for census blockgroups through the API.
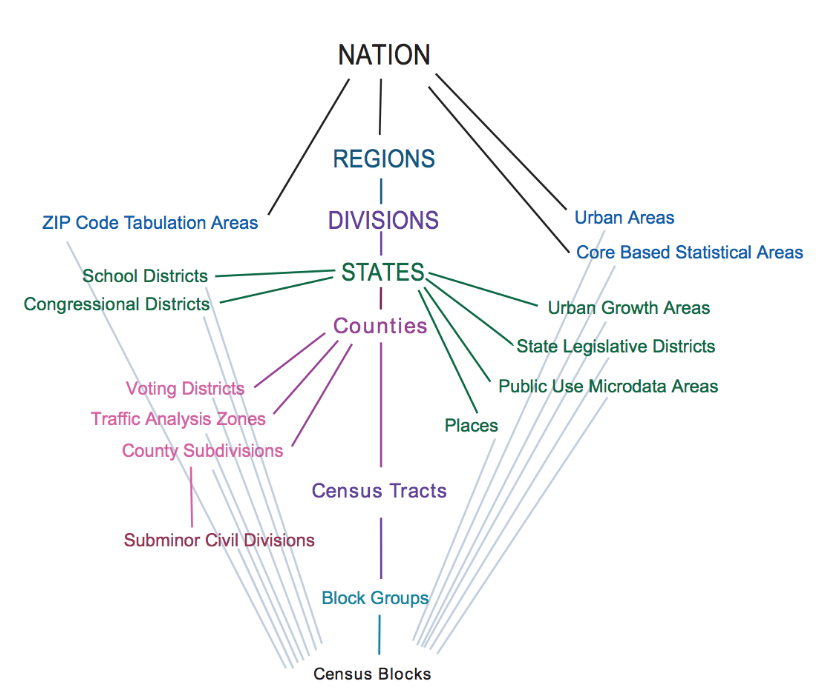
3. Variables
Meanwhile, another API call grabs the complete list of variables for the planning database. These are filtered based on my own generalizations as well as built-in user choice. Unfortunately, the US Census API only supports queries with up to 50 variables, so the hundreds of variables that make up the database schema must be pared down. Finally, a list of variables is built and sent to the next API call.
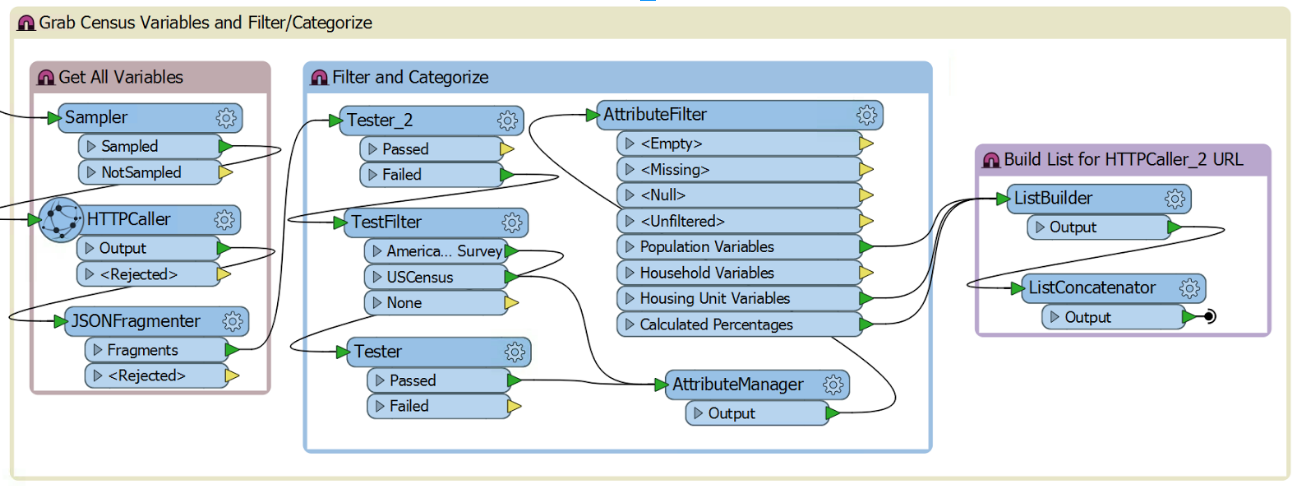
4. Planning database query
Spatial data from TIGERWeb and the previously chosen variables come together to form the new URL for the data API call.
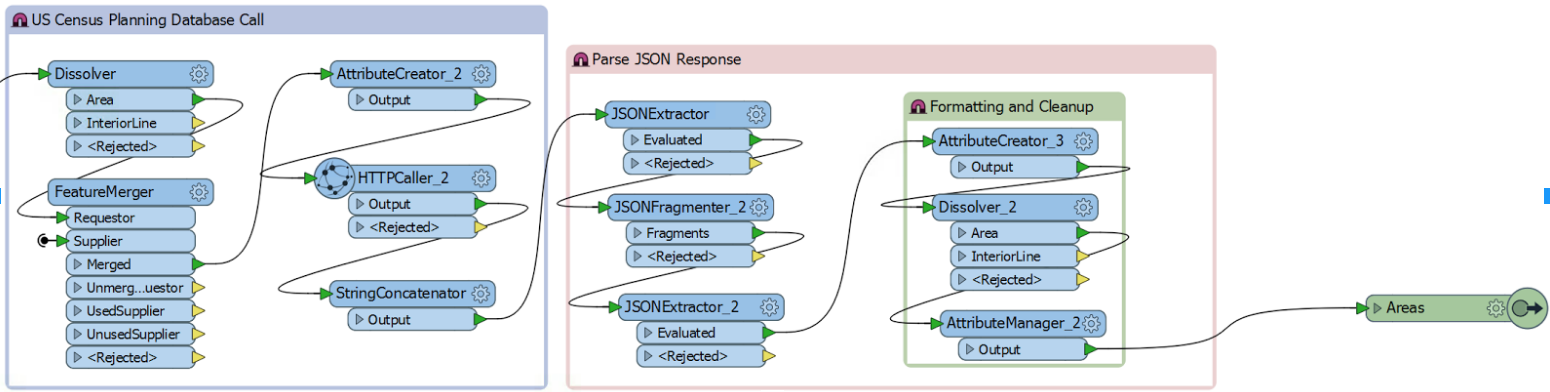
5. JSON response manipulation
JSON has been the common response throughout the USCensusCaller. Because the response from the US Census API is a JSON array rather than an object, the final extraction is inelegant, but it works! Two JSONExtractors and a JSONFragmenter do the heavy lifting, and after a bit of cleanup, the data is ready for output.
The results are a combination of areas (census blockgroup polygons) and points, which in my example are coffee shops. Each area now has census variables as attributes. These attributes could be further spatially joined to the original stores if desired.
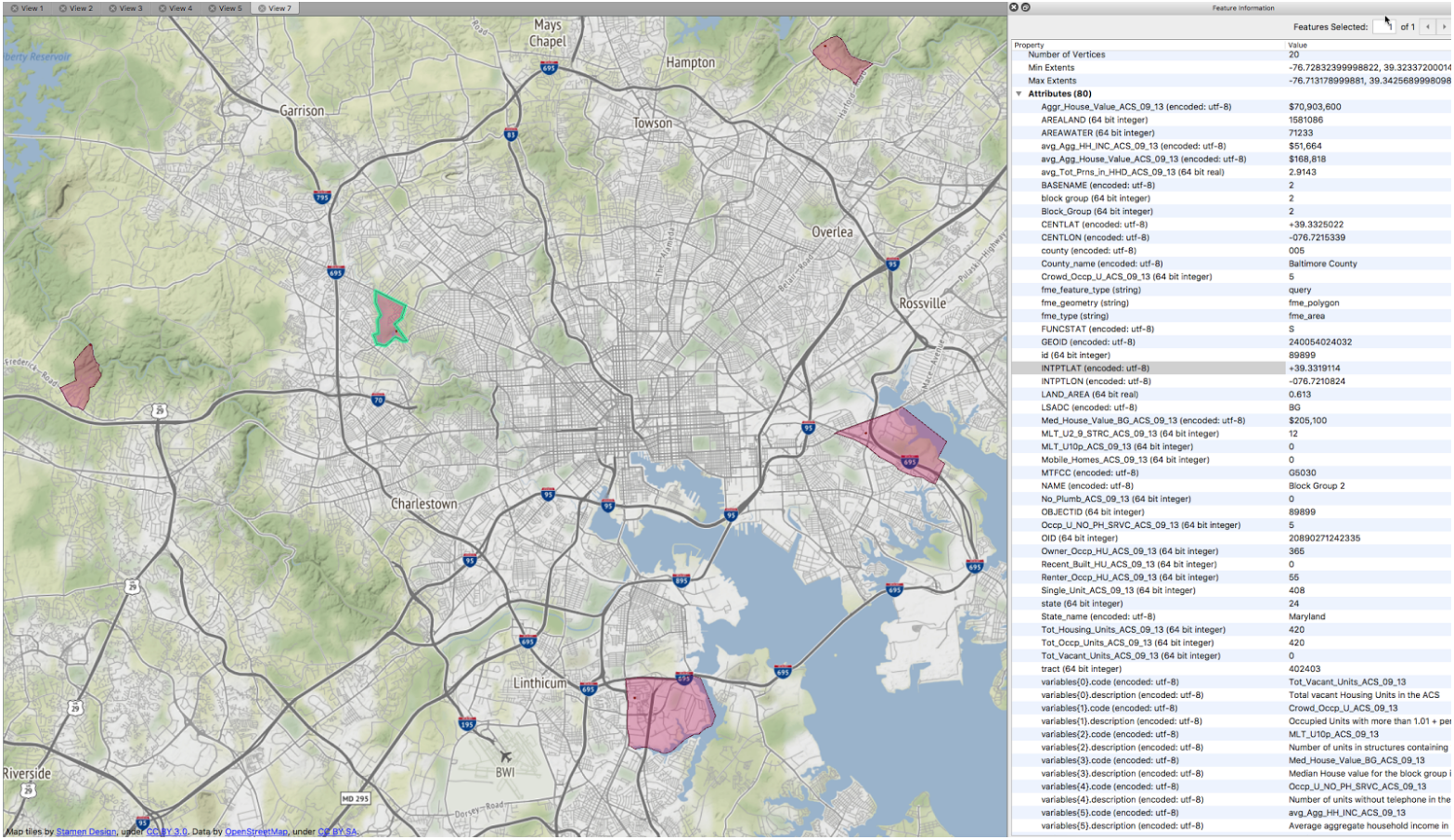
The Future
While taking advantage of open data sources isn’t new or unique to us at Safe Software, I consider this project a small step in a new and interesting direction. With important players like Tableau, Alteryx, Insights, and various data vendors all working in this space, it’s fitting that FME’s versatility would be up to the challenge.
The USCensusCaller is not yet as sophisticated as it could be, but for simple questions like, “Which of my potential sites is the best place to put a new trendy coffee shop based on local income, real estate cost, resident age, and education?” or even “What is the demographic makeup of my neighbourhood?” it is an excellent starting point.
P.S. A similar solution is currently unavailable for our Canadian friends. But perhaps not forever as changes are made to the StatCan API.

Nathan Hildebrand
Nathan is an FME Server Technology Expert with a background in GIS, English, and forestry. Before Safe, Nathan spent time replenishing our forests with trees (he’s planted over 250,000!). When Nathan’s not in the forest, and not answering your questions, you might find him puttering through some Mozart on his French horn.



