 I recently taught the performance chapter of our FME Desktop advanced training course and got into a conversation with a student about creative ways to use parallel processing. Some of the ideas we came up with about generating ‘groups’ were so interesting I thought I would share them.
I recently taught the performance chapter of our FME Desktop advanced training course and got into a conversation with a student about creative ways to use parallel processing. Some of the ideas we came up with about generating ‘groups’ were so interesting I thought I would share them.
I start here with a bring description of what parallel processing is in FME, then three tips for setting it up in innovative ways.
![]()
Parallel Processing: An Introduction
To quickly bring you up to speed on parallel processing in general you’ll notice that many group-based FME transformers have a parameter for turning on parallel processing when a group by is set:
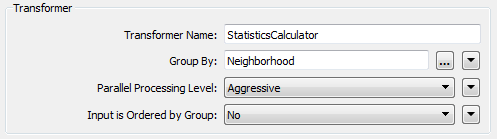
Here I am creating statistics on park features in Vancouver. I have the group-by set to Neighborhood which means that each neighborhood gets its own set of statistics.
Because I have parallel processing turned on, instead of processing this as a single set of features in a single serial process, FME will split the data up, create a separate process per group, and run all those processes in parallel. Ideally the translation will run much faster this way (to ensure this it’s better to have fewer, but larger, groups than many small ones).
So that’s parallel processing in a nutshell. Normally you can only implement parallel processing when there is a group-by parameter set, but there are ways to manage this even when you don’t have a suitable group-by attribute.
![]()
Parallel Processing: Artificial Groups
You may already know this because I’ve certainly mentioned it before, but if you don’t have an attribute to group by for parallel processing, the simplest way is to make one up.
Here’s an example. I have 13,597 address records and am creating a buffer around each:

I don’t have an attribute to group-by. So I make one up with a ModuloCounter transformer:
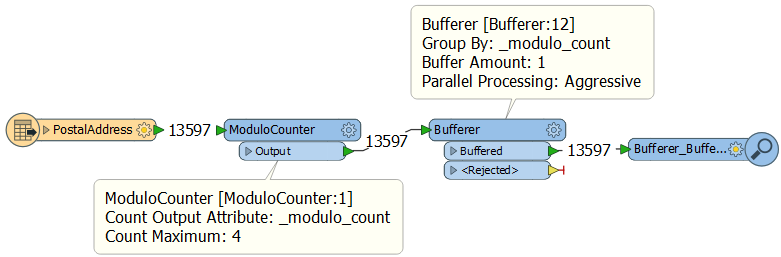
The ModuloCounter transformer counts like the Counter, but only to a maximum number, then it restarts the sequence. Here I am numbering my features 0,1,2,3,0,1,2,3,0,1,2,3,0,1,2,3,etc
Now I can use that modulo number in the Bufferer as a group-by and transform the data with 4 parallel processes (four because the ModuloCounter counts to a maximum of 4). I can use this technique on any transformer with a group-by and parallel processing.
However! There are limitations. For example, the Bufferer merges together overlapping buffers when they are part of a group. If I don’t want that merging to take place then I can only use this technique where I know that the buffers are too small (say 1 metre) to overlap; or when I am going to follow up with a Dissolver to merge overlaps together anyway.
In short, this only works when the groups don’t need to interact or it doesn’t matter if they do. I wouldn’t do this, for example, when I want to create individual, overlapping buffers. I also might not use this in a Dissolver transformer where two features that should be dissolved could end up in different groups.
Another limitation is that it only works for transformers with a single input port; but during the training we came up with a solution for that…
![]()
Parallel Processing: Artificial Groups for Two Port Transformers
Let’s look at a different example, this time the PointOnAreaOverlayer:
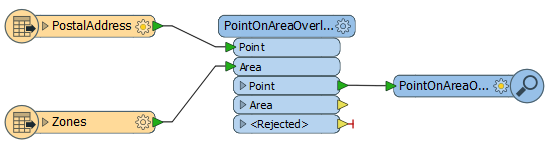
I want to find which zone each address falls in (let’s say it’s their garbage collection zone). Creating an artificial group for parallel processing is more difficult because there are two input ports. If I only give a modulo number to the addresses, they won’t match in a group with the zones, and if I give a modulo number to each, how do I know that the zone an address falls in will be in the same group?
The solution? A bit of brute force:
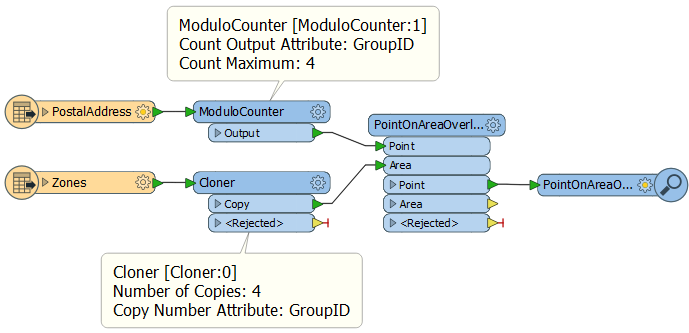
I split the address points into four, but I use the Cloner to create 4 copies of the zone polygons. That way each address group is given its own set of zones and will find the proper match, regardless of which group it is in. Now I can apply parallel processing in the PointOnAreaOverlayer using GroupID as the group-by:
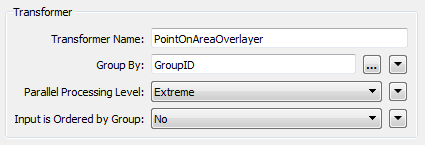
It’s brute force because cloning data is not subtle! But there are a few details you should look more closely at…
Firstly, I don’t need to give a modulo number to the zones because the Cloner already gives them that as a Copy Number attribute. But notice that the attributes created by Cloner and ModuloCounter are given the same name (GroupID) and secondly they both count up to the same number (in other words create as many clones as the ModuloCounter counts to, here four).
Secondly, I use the ModuloCounter on the larger group of features (13,500+ addresses) and use the Cloner on the smaller group (6 garbage zones), because it’s not too big a deal if I clone just 6 features. So the limitation here is one of scaling. I can scale up the address features in my example, and that is fine – in fact the more addresses the more efficient it becomes to parallel process them – but scaling up the cloned features (the zones in my example) is going to cause a performance hit.
So we put our heads together and came up with a different solution to that…
![]()
Parallel Processing: Artificial Groups for Spatial Processing
Let’s take that PointOnAreaOverlayer example now and scale it up. Let’s say – as the student suggested – that there are 700,000+ parcels and 750,000+ address points. I wouldn’t want to start cloning 700,000 polygon features as that would almost certainly negate any benefits of parallel processing.
Is there another way? I think so. The idea is to tile the data. Here’s what I came up with:
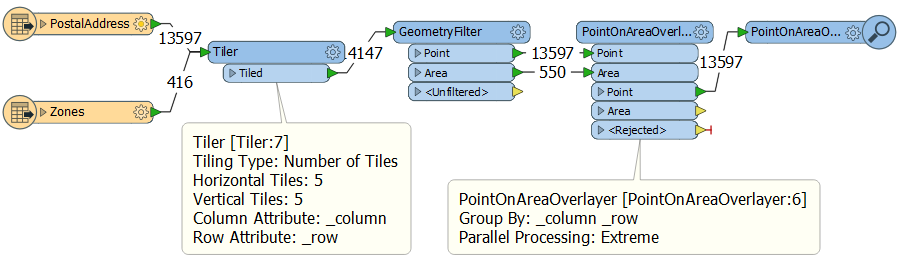
Here I tile all my data before pushing it into PointOnAreaOverlayer and grouping by the tile row and column IDs. In a 5×5 grid that gives me 25 processes that I can run in parallel (up to a maximum of 16 at a time on my computer).
But can I do that and still expect correct results? In this case I think the answer is yes because spatially chopping the data into tiles has no effect on a PointOnAreaOverlayer. If I have a point that falls inside a polygon, even if that polygon is split up into pieces, the point will still fall inside part of the polygon and retrieve the same attributes.
In this example I am only keeping the points, so if the areas are tiled there is no problem. If I wanted to keep the areas then I could either a) Keep a copy of the original geometry and then restore it (GeometryExtractor/GeometryReplacer) or b) Just use a FeatureMerger to merge the tiled areas with their new attributes back onto the original features. For the record, I prefer ‘b’.
The effectiveness of the process depends on how many tiles I create and how many features fall inside them. I don’t want to create so many tiles that they don’t have enough content to be worthwhile processing in parallel; but I also don’t want to create too few tiles that I am not making efficient use of my processing cores. It’s a balancing act. Four tiles might be enough for a city-level project, but at the country level you might want 20-30 tiles (incidentally, although I did 5×5 it doesn’t have to be symmetrical like that).
The limitation here goes back to the problem of which features fall inside which group. For example I wouldn’t try this with an AnchoredSnapper because there the cut boundary could have an effect. For example, a candidate very close to the boundary would be forced to snap to an anchor in the same tile, when the closest anchor might be in the neighboring tile.
![]()
Summary
I’ve saved these workspaces as templates for you to download and try for yourself:
- Example 1: The ModuloCounter
- Example 2: The ModuloCounter/Cloner Combination
- Example 3: The Tiler
When you run them, will they be quicker than without parallel processing? Well, probably not. But that’s because I’m using small amounts of data just to demonstrate a technique. Parallel processing is really only effective when the quantity of data is large enough to overcome the time required to start/stop a separate processing.
But that’s OK. The point is to show you some techniques that might scale up to improve performance on your larger projects.
The one thing you must do is to think hard about whether the techniques will work for your scenario. If you create artificial groups for parallel processing you have to be sure that it doesn’t matter which group a feature falls inside.
If something here was useful, please do let me know. I’m interested in both how you used it but also whether it’s useful to post more of these “idea” type articles.
Regards


Mark Ireland
Mark, aka iMark, is the FME Evangelist (est. 2004) and has a passion for FME Training. He likes being able to help people understand and use technology in new and interesting ways. One of his other passions is football (aka. Soccer). He likes both technology and soccer so much that he wrote an article about the two together! Who would’ve thought? (Answer: iMark)



